
by John Halamka, Life as a Healthcare CIO
We began the meeting by relating our standards trajectory to today's agenda.
Our outstanding standards issues for discussion include
1. Content
Continued discussion of GreenCDA on the wire and overview of Stan Huff's CIMI initiative
Standardizing DICOM image objects for image sharing and investigating other possible approaches (e.g., cloud based JPEG2000 exchange). Consider image transfer standards, image viewing standards, and image reporting standards.
Query Health i.e. I2B2 distributed queries that send questions to data instead of requiring consolidation of data
Simplify the specification for quality measures to enhance consistency of implementation.
The December meeting included an overview of Query Health and Quality measure standards, leaving the discussion of GreenCDA/CIMI and DICOM to our 2012 meetings.
2. Vocabulary
Extend the quality measurement vocabularies to clinical summaries
Lab ordering compendium
The December meeting included a discussion of the lab ordering compendium, leaving the discussion of clinical summary vocabularies to our 2012 meetings.
3. Transport
Specify how the metadata ANPRM be integrated into the health exchange architecture
Additional NwHIN standards development (hearing re Exchange specification complexity, review/oversight of the S&I framework work on Exchange specifications simplification). Further define secure RESTful transport standards.
Accelerate provider directory pilots (Microdata, RESTful query/response that separates the transaction layer from the schema) and rapidly disseminate lessons learned.
The December meeting included an update on the provider directory and certificate components of transport
Our first presentation was an NCVHS update on ACA Section 10109 by Walter Suarez.
The Committee emphasized the need to coordinate NCHVS work and HITSC work given that division between administrative and clinical data is becoming less distinct over time
Our second presentation was an Implementation Workgroup Update by Liz Johnson about testing procedures that support the certification process.
The committee emphasized the need to pilot these procedures, ensuring they are as simple as possible and reflect a practical evaluation of the functionality intended to support policy goals.
Next, Doug Fridsma and Rich Elmore gave an ONC update. Rich Elmore described the Query Health initiative, as referenced in my previous blog post about sending questions to data (rather than sending data to registries).
The committee endorsed the work and noted that further research will be needed to link patients across multiple databases to avoid double counting individuals in quality measure denominators. The work of Jeff Jonas, as described in my earlier blog post about linking identity.
Doug updated the committee about the S&I Framework initiatives - Transitions of Care, Lab Results, Provider Directories, Data Segmentation (for privacy protection), and electronic submission of medical documentation for Medicare review.
We then discussed a preliminary framework for HITSC 2012 Workplan to ensure the items in the standards trajectory listed above are completed in 2012 as we continue to prepare for meaningful use stage 3.
A great meeting.
Wednesday, December 14, 2011
Monday, December 12, 2011
The Elephant in the Room
Why aren't we talking about pricing failures? The US, has consistently higher prices than any other country. The 2010 report by the International Federation of Health Plans consists of 23 pricing measures and the pattern is the same across each of these measures. And a 2010 investigation of Health Care Cost Trends and Cost Drivers in Massachusetts found that "price variations are correlated to market leverage..."
Before his departure from CMS, Don Berwick was interviewed by the New York Times and took a "parting shot at waste". Berwick listed five elements of waste including overtreatment of patients, failure to coordinate care, administrative complexity, burdensome rules and fraud. Pricing failures didn't make the list. (Many folks have commented and analyzed the five factors including John Halamka's terrific piece on how EHRs can address these 5 factors.)
Then in Berwick's December 7th speech to the IHI National Forum, he adds a sixth element:
Don Berwick defines pricing failures as "the waste that comes as prices migrate far from the actual costs of production plus fair profits." Think about that: "far from the actual costs of production plus fair profits". At a time when total healthcare expenditures consume a huge share of GDP and increasing at rates higher than inflation and wage increases, why haven't pricing failures been on the table? As we struggle to control costs and improve quality, there is intense focus on utilization, regulation and care coordination. Why not also focus on pricing failures?
So why hasn't pricing failures been part of the conversation up to now? Here's how the conversation usually proceeds: Health Affairs November 2011 article, Large Variations In Medicare Payments For Surgery Highlight Savings Potential From Bundled Payment Programs, "found that current Medicare episode payments for certain inpatient procedures varied by 49–130 percent across hospitals sorted into five payment groups. Intentional differences in payments attributable to such factors as geography or illness severity explained much of this variation. But after adjustment for these differences, per episode payments to the highest-cost hospitals were higher than those to the lowest-cost facilities by up to $2,549 for colectomy and $7,759 for back surgery."
Sounds like a clarion call for a focus on pricing failures doesn't it? Actually, no... The authors conclusions only speak to cost efficiency and utilization. "Our study suggests that bundled payments could yield sizable savings for payers, although the effect on individual institutions will vary because hospitals that were relatively expensive for one procedure were often relatively inexpensive for others. More broadly, our data suggest that many hospitals have considerable room to improve their cost efficiency for inpatient surgery and should look for patterns of excess utilization, particularly among surgical specialties, other inpatient specialist consultations, and various types of postdischarge care."
So is it time to broaden the conversation to include pricing failures? At least one health system has realized that "the jig is up". Perhaps it's time to peel the onion a bit... And take a serious look at pricing failures which deviate "far from the actual costs of production plus fair profits".
_______________________________
Background tables from the IFHP report:
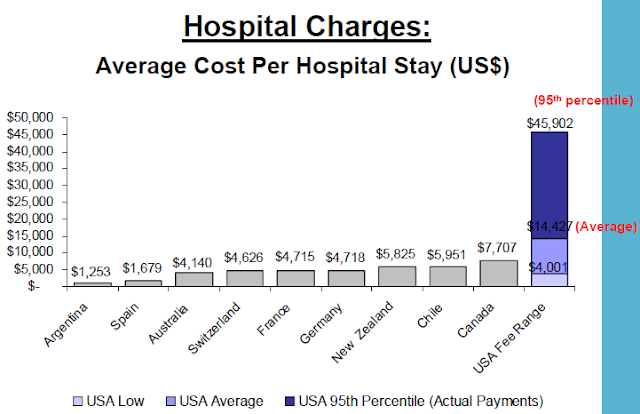
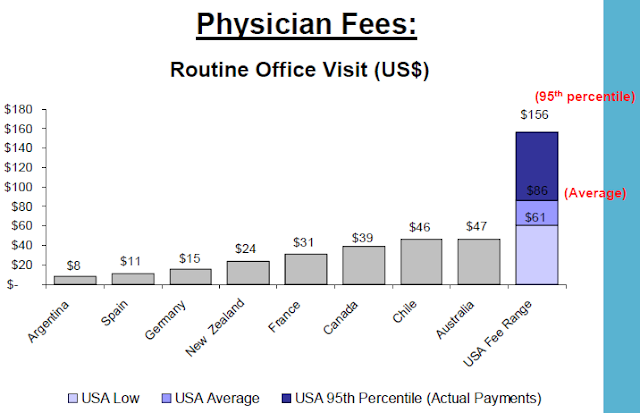
Before his departure from CMS, Don Berwick was interviewed by the New York Times and took a "parting shot at waste". Berwick listed five elements of waste including overtreatment of patients, failure to coordinate care, administrative complexity, burdensome rules and fraud. Pricing failures didn't make the list. (Many folks have commented and analyzed the five factors including John Halamka's terrific piece on how EHRs can address these 5 factors.)
Then in Berwick's December 7th speech to the IHI National Forum, he adds a sixth element:
- "Overtreatment – the waste that comes from subjecting people to care that cannot possibly help them – care rooted in outmoded habits, supply-driven behaviors, and ignoring science.
- Failures of Coordination- the waste that comes when people – especially people with chronic illness – fall through the slats. They get lost, forgotten, confused. The result: complications, decays in functional status, hospital readmissions, and dependency.
- Failures of Reliability – the waste that comes with poor execution of what we know to do. The result: safety hazards and worse outcomes.
- Administrative Complexity – the waste that comes when we create our own rules that force people to do things that make no sense – that converts valuable nursing time into meaningless charting rituals or limited physician time into nonsensical and complex billing procedures.
- Pricing Failures – the waste that comes as prices migrate far from the actual costs of production plus fair profits.
- Fraud and Abuse – the waste that comes as thieves steal what is not theirs, and also from the blunt procedures of inspection and regulation that infect everyone because of the misbehaviors of a very few. We have estimated how big this waste is – from both the perspective of the Federal payers – Medicare and Medicaid – and for all payers."
Don Berwick defines pricing failures as "the waste that comes as prices migrate far from the actual costs of production plus fair profits." Think about that: "far from the actual costs of production plus fair profits". At a time when total healthcare expenditures consume a huge share of GDP and increasing at rates higher than inflation and wage increases, why haven't pricing failures been on the table? As we struggle to control costs and improve quality, there is intense focus on utilization, regulation and care coordination. Why not also focus on pricing failures?
So why hasn't pricing failures been part of the conversation up to now? Here's how the conversation usually proceeds: Health Affairs November 2011 article, Large Variations In Medicare Payments For Surgery Highlight Savings Potential From Bundled Payment Programs, "found that current Medicare episode payments for certain inpatient procedures varied by 49–130 percent across hospitals sorted into five payment groups. Intentional differences in payments attributable to such factors as geography or illness severity explained much of this variation. But after adjustment for these differences, per episode payments to the highest-cost hospitals were higher than those to the lowest-cost facilities by up to $2,549 for colectomy and $7,759 for back surgery."
Sounds like a clarion call for a focus on pricing failures doesn't it? Actually, no... The authors conclusions only speak to cost efficiency and utilization. "Our study suggests that bundled payments could yield sizable savings for payers, although the effect on individual institutions will vary because hospitals that were relatively expensive for one procedure were often relatively inexpensive for others. More broadly, our data suggest that many hospitals have considerable room to improve their cost efficiency for inpatient surgery and should look for patterns of excess utilization, particularly among surgical specialties, other inpatient specialist consultations, and various types of postdischarge care."
So is it time to broaden the conversation to include pricing failures? At least one health system has realized that "the jig is up". Perhaps it's time to peel the onion a bit... And take a serious look at pricing failures which deviate "far from the actual costs of production plus fair profits".
_______________________________
Background tables from the IFHP report:
Monday, November 21, 2011
The November HIT Standards Committee
by John Halamka, Life as a Healthcare CIO, November 16, 2011
Today, the HIT Standards Committee shifted gears from the Summer Camp work on Meaningful Use Stage 2 and began new interoperability efforts.
We began the meeting with a presentation by Liz Johnson and Judy Murphy about the Implementation Workgroup's recommendations to improve the certification and testing process. These 15 items incorporate the Stage 1 experience gathered from numerous hospitals and eligible professionals. If ONC and NIST can implement this plan, many stakeholders will benefit. The Committee approved these recommendations without revision.
Next, we focused on content, vocabulary and transport standards.
In my October HIT Standards Committee blog post, I noted that HITSC should work on the following projects:
Content
*Continued refinement of the Consolidated CDA implementation guides and tools to enhance semantic interoperability including consistent use of business names in "Green" over-the-wire standards.
*Simplifying the specification for quality measures to enhance consistency of implementation.
*Standardizing DICOM image objects for image sharing and investigating other possible approaches. We'll review image transfer standards, image viewing standards, and image reporting standards.
*Query Health - distributed queries that send questions to data instead of requiring consolidation of the data
Vocabulary
*Extending the quality measurement vocabularies to clinical summaries
*Finalizing a standardized lab ordering compendium
Transport
*Specifying how the metadata ANPRM be integrated into health exchange architectures
*Supporting additional NwHIN standards development (hearings about Exchange specification complexity, review/oversight of the S&I Framework projects on simplification of Exchange specifications). Further defining secure RESTful transport standards.
*Accelerating provider directory pilots (Microdata, RESTful query/response that separates the transaction layer from the schema) and rapidly disseminating lessons learned.
The November Committee agenda included a discussion of Consolidated CDA, Quality Measures, and NwHIN Implementation Guides.
Doug Fridsma began with a discussion of the Consolidated CDAwork and the tools which support it.
The Committee had a remarkable dialog with more passion and unanimity than at any recent discussion. We concluded:
*Simple XML that is easily implemented will accelerate adoption
*That simple XML should be backed by a robust information model. However, implementers should not need expert knowledge of that model. The information model can serve as a reference for SDOs to guide their work
*Detailed Clinical Models, as exemplified by Stan Huff's Clinical Information Modeling Initiative (CIMI) hold great promise. Stan has assembled an international consensus group including those who work on
-Archetype Object Model/ADL 1.5 openEHR
-CEN/ISO 13606 AOM ADL 1.4
-UML 2.x + OCL + healthcare extensions
-OWL 2.0 + healthcare profiles and extensions
-MIF 2 + tools HL7 RIM – static model designer
Their work may be much more intuitive than today's HL7 RIM as the basis for future clinical exchange standards.
*Rather than debate whether Consolidated CDA OR GreenCDA(simplified XML tagging) should be the over the wire format, the Committee noted that "OR" really implies "AND" for vendors and increases implementation burden. The Committee endorsed moving forward with GreenCDA as the single over the wire format.
*We should move forward now with this work, realizing that it will take 9-12 months and likely will not be included in Meaningful Use Stage 2, but it is the right thing to do.
Thus, the future Transfer of Care Summary will be assembled from a simple set of clinically relevant GreenCDA templates, based on CIMI models, as needed to support various use cases. There will be no optionality - just a single way to express medical concepts in specific templates.
To support this approach, we'll need great modeling tools. David Carlson and John Timm presented the applications developed to support the VA's Model Driven Health Tools initiative. This software turns clinical models into XML and conformance testing tools. The committee was very impressed.
Next, Avinash Shanbhag presented the ONC work on Quality Measures that seeks to ensure quality numerators and denominators are expressed in terms of existing EHR data elements captured as part of standard patient care workflows.
Avinash also presented an update on transport efforts, which include easy to use, well documented implementation guides for SMTP/SMIME and SOAP. The work is highly modular and does not require that the full suite of NwHIN Exchange specifications be implemented for SOAP exchanges.
As part of the ongoing efforts to improve NwHIN Exchange, the HIT Standards Committee is seeking input from NwHIN implementers per this blog post.
Finally, Wil Yu updated the committee on the SHARP and other innovation programs.
There will be a great body of challenging work to do in 2012. What's needed after that? The next 5 years will include many new regulations as healthcare reform is rolled out. It's clear that the Standards Committee will have many topics to discuss.
Today, the HIT Standards Committee shifted gears from the Summer Camp work on Meaningful Use Stage 2 and began new interoperability efforts.
We began the meeting with a presentation by Liz Johnson and Judy Murphy about the Implementation Workgroup's recommendations to improve the certification and testing process. These 15 items incorporate the Stage 1 experience gathered from numerous hospitals and eligible professionals. If ONC and NIST can implement this plan, many stakeholders will benefit. The Committee approved these recommendations without revision.
Next, we focused on content, vocabulary and transport standards.
In my October HIT Standards Committee blog post, I noted that HITSC should work on the following projects:
Content
*Continued refinement of the Consolidated CDA implementation guides and tools to enhance semantic interoperability including consistent use of business names in "Green" over-the-wire standards.
*Simplifying the specification for quality measures to enhance consistency of implementation.
*Standardizing DICOM image objects for image sharing and investigating other possible approaches. We'll review image transfer standards, image viewing standards, and image reporting standards.
*Query Health - distributed queries that send questions to data instead of requiring consolidation of the data
Vocabulary
*Extending the quality measurement vocabularies to clinical summaries
*Finalizing a standardized lab ordering compendium
Transport
*Specifying how the metadata ANPRM be integrated into health exchange architectures
*Supporting additional NwHIN standards development (hearings about Exchange specification complexity, review/oversight of the S&I Framework projects on simplification of Exchange specifications). Further defining secure RESTful transport standards.
*Accelerating provider directory pilots (Microdata, RESTful query/response that separates the transaction layer from the schema) and rapidly disseminating lessons learned.
The November Committee agenda included a discussion of Consolidated CDA, Quality Measures, and NwHIN Implementation Guides.
Doug Fridsma began with a discussion of the Consolidated CDAwork and the tools which support it.
The Committee had a remarkable dialog with more passion and unanimity than at any recent discussion. We concluded:
*Simple XML that is easily implemented will accelerate adoption
*That simple XML should be backed by a robust information model. However, implementers should not need expert knowledge of that model. The information model can serve as a reference for SDOs to guide their work
*Detailed Clinical Models, as exemplified by Stan Huff's Clinical Information Modeling Initiative (CIMI) hold great promise. Stan has assembled an international consensus group including those who work on
-Archetype Object Model/ADL 1.5 openEHR
-CEN/ISO 13606 AOM ADL 1.4
-UML 2.x + OCL + healthcare extensions
-OWL 2.0 + healthcare profiles and extensions
-MIF 2 + tools HL7 RIM – static model designer
Their work may be much more intuitive than today's HL7 RIM as the basis for future clinical exchange standards.
*Rather than debate whether Consolidated CDA OR GreenCDA(simplified XML tagging) should be the over the wire format, the Committee noted that "OR" really implies "AND" for vendors and increases implementation burden. The Committee endorsed moving forward with GreenCDA as the single over the wire format.
*We should move forward now with this work, realizing that it will take 9-12 months and likely will not be included in Meaningful Use Stage 2, but it is the right thing to do.
Thus, the future Transfer of Care Summary will be assembled from a simple set of clinically relevant GreenCDA templates, based on CIMI models, as needed to support various use cases. There will be no optionality - just a single way to express medical concepts in specific templates.
To support this approach, we'll need great modeling tools. David Carlson and John Timm presented the applications developed to support the VA's Model Driven Health Tools initiative. This software turns clinical models into XML and conformance testing tools. The committee was very impressed.
Next, Avinash Shanbhag presented the ONC work on Quality Measures that seeks to ensure quality numerators and denominators are expressed in terms of existing EHR data elements captured as part of standard patient care workflows.
Avinash also presented an update on transport efforts, which include easy to use, well documented implementation guides for SMTP/SMIME and SOAP. The work is highly modular and does not require that the full suite of NwHIN Exchange specifications be implemented for SOAP exchanges.
As part of the ongoing efforts to improve NwHIN Exchange, the HIT Standards Committee is seeking input from NwHIN implementers per this blog post.
Finally, Wil Yu updated the committee on the SHARP and other innovation programs.
There will be a great body of challenging work to do in 2012. What's needed after that? The next 5 years will include many new regulations as healthcare reform is rolled out. It's clear that the Standards Committee will have many topics to discuss.
Monday, November 14, 2011
The Elephant in the Room: The Prequel
At the October HIT Policy Committee, Charles Kennedy described his work with health systems establishing accountable care models. His clients "have actual health plan products that are private labeled products with the delivery systems' name on it that they’re selling."
Kenedy talked with the COO of one health system that was particularly high cost. Kennedy asked the COO: "Why on earth would you want to form an ACO? You’re a monopoly. You’re making tons of money. You can keep doing this for some period of time."
The COO replied “Look I understand that the jig is up.”
The COO went on to say "I know how to take $60 out per member per month. $60 - - out of my cost structure. I know exactly how to do it. I never had a motivation to do it before - - until health care reform happened." Kennedy explained that the COO has now "taken those costs out of his delivery system and because he has a product in the marketplace he gets to reap those efficiencies. The second thing he said was that 'I never really had a use for health IT until I began to take costs out of my infrastructure'."
Kenedy talked with the COO of one health system that was particularly high cost. Kennedy asked the COO: "Why on earth would you want to form an ACO? You’re a monopoly. You’re making tons of money. You can keep doing this for some period of time."
The COO replied “Look I understand that the jig is up.”
The COO went on to say "I know how to take $60 out per member per month. $60 - - out of my cost structure. I know exactly how to do it. I never had a motivation to do it before - - until health care reform happened." Kennedy explained that the COO has now "taken those costs out of his delivery system and because he has a product in the marketplace he gets to reap those efficiencies. The second thing he said was that 'I never really had a use for health IT until I began to take costs out of my infrastructure'."
Wednesday, October 12, 2011
Query Health at the September HIT Policy Committee Meeting
Today the HIT Policy Committee is considering the Privacy and Security Tiger Team recommendations on the Query Health policy sandbox.
By way of background, here are the minutes from last month's introductory discussion from the September HIT Policy Committee:
Richard Elmore of ONC presented on Query Health, recently launched initiative to develop standards and services for distributed population queries. Guidance from and linkage to the HITPC will be crucial to the success of this effort. Elmore presented the vision of Query Health as follows: ―Enable a learning health system to understand population measures of health, performance, disease, and quality, while respecting patient privacy, to improve patient and population health and reduce costs.
The nation is reaching a critical mass of deployed EHRs with greater standardization of information in support of HIE and quality measure reporting. There is an opportunity to improve community understanding of population health, performance, and quality through:
Elmore commented that the challenges include the high transaction and ―plumbing‖ costs associated with variation in clinical concept coding (even within organizations), the lack of query standards, and the lack of understanding best business practices. There is also a centralizing tendency that moves data further away from the source, increases personal health information exposure, and limits responsiveness to patient consent preference. Another challenge is that the work done to date, with a few exceptions, has been limited to larger health systems (with large IT and/or research budgets).
The goal is to improve the community understanding of patient population health to be able to ask a question, whether it is to a small physician’s office or a larger hospital, and obtain an aggregate result back. Questions could focus on disease outbreaks, prevention activities, research, quality measures, etc. With regard to scope and approach, Elmore explained that Query Health is being structured in a way that is similar to the Direct Project. It is a public-private partnership project focusing on the standards and services related to distributed population queries. The concept is to have an open, democratic, community-driven consensus-based process. There is a critical linkage with the HITPC and Privacy and Security Tiger Team to provide the guidance needed to drive this project.
Elmore reviewed a series of user stories to demonstrate how to adjust queries with simple, secure use cases to establish the standards and protocols for patient data that is going to be queried against, the query and case definition, and then getting the results back to the requestor of the information.
The organization has a voting group of committed members, the Query Health Implementation Group. There are three workgroups (Clinical Workgroup, Technical Workgroup, and Business Workgroup). In terms of timeline, Query Health is at the requirements and specification stage (the next steps are approaching consensus, and undergoing pilots). Query Health was designed with goals alignment with the S&U Framework, as an open government initiative that is engaging a wide variety of stakeholders. Query Health is also aligned with meaningful use and various standards, as well as with one of ONC’s major strategies, the digital infrastructure for a learning health system.
Elmore described the Summer Concert Series, a presentation by the practitioners that have working on distributor queries that highlights the importance of this project. Through this event, a number of challenges were identified, including best practices for data use/sharing, sustainability, auditability, etc.
It is hoped that the HITPC and Privacy and Security Tiger Team will provide Query Health with policy guidance and will monitor Query Health’s progress. It is anticipated that the first activity with which Query Health will be looking for such guidance is in the policy sandbox and to ensure that the project is safe, cautious, and conservative for the purposes of starting that initial pilot work. The initial set of policy sandbox ideas has been modeled after previous S&I Framework initiatives in consultation with ONC policy and privacy and S&I Framework leaders and their staff. The concept is that query requests and responses will be implemented in the pilot to use the least identifiable form of health data necessary in the aggregate within the following guidelines: (1) a disclosing entity should have its queries and results under their control (manual or automated); (2) the data being exchanged will be mock or test data, aggregated de-identified data sets or aggregated limited data sets, each with data use agreements; and (3) for other than regulated/permitted use purposes, cells with less than five observations in a cell shall be blurred by methods that reduce the accuracy of the information provided.
Discussion
By way of background, here are the minutes from last month's introductory discussion from the September HIT Policy Committee:
Richard Elmore of ONC presented on Query Health, recently launched initiative to develop standards and services for distributed population queries. Guidance from and linkage to the HITPC will be crucial to the success of this effort. Elmore presented the vision of Query Health as follows: ―Enable a learning health system to understand population measures of health, performance, disease, and quality, while respecting patient privacy, to improve patient and population health and reduce costs.
The nation is reaching a critical mass of deployed EHRs with greater standardization of information in support of HIE and quality measure reporting. There is an opportunity to improve community understanding of population health, performance, and quality through:
- Enabling proactive patient care in the community
- Delivering insights for local and regional quality improvement
- Facilitating consistently applied performance measures and payment strategies for the community (hospital, practice, health exchange, state, payer, etc.) based on aggregated, de-identified data
- Identifying treatments that are most effective for the community.
Elmore commented that the challenges include the high transaction and ―plumbing‖ costs associated with variation in clinical concept coding (even within organizations), the lack of query standards, and the lack of understanding best business practices. There is also a centralizing tendency that moves data further away from the source, increases personal health information exposure, and limits responsiveness to patient consent preference. Another challenge is that the work done to date, with a few exceptions, has been limited to larger health systems (with large IT and/or research budgets).
The goal is to improve the community understanding of patient population health to be able to ask a question, whether it is to a small physician’s office or a larger hospital, and obtain an aggregate result back. Questions could focus on disease outbreaks, prevention activities, research, quality measures, etc. With regard to scope and approach, Elmore explained that Query Health is being structured in a way that is similar to the Direct Project. It is a public-private partnership project focusing on the standards and services related to distributed population queries. The concept is to have an open, democratic, community-driven consensus-based process. There is a critical linkage with the HITPC and Privacy and Security Tiger Team to provide the guidance needed to drive this project.
Elmore reviewed a series of user stories to demonstrate how to adjust queries with simple, secure use cases to establish the standards and protocols for patient data that is going to be queried against, the query and case definition, and then getting the results back to the requestor of the information.
The organization has a voting group of committed members, the Query Health Implementation Group. There are three workgroups (Clinical Workgroup, Technical Workgroup, and Business Workgroup). In terms of timeline, Query Health is at the requirements and specification stage (the next steps are approaching consensus, and undergoing pilots). Query Health was designed with goals alignment with the S&U Framework, as an open government initiative that is engaging a wide variety of stakeholders. Query Health is also aligned with meaningful use and various standards, as well as with one of ONC’s major strategies, the digital infrastructure for a learning health system.
Elmore described the Summer Concert Series, a presentation by the practitioners that have working on distributor queries that highlights the importance of this project. Through this event, a number of challenges were identified, including best practices for data use/sharing, sustainability, auditability, etc.
It is hoped that the HITPC and Privacy and Security Tiger Team will provide Query Health with policy guidance and will monitor Query Health’s progress. It is anticipated that the first activity with which Query Health will be looking for such guidance is in the policy sandbox and to ensure that the project is safe, cautious, and conservative for the purposes of starting that initial pilot work. The initial set of policy sandbox ideas has been modeled after previous S&I Framework initiatives in consultation with ONC policy and privacy and S&I Framework leaders and their staff. The concept is that query requests and responses will be implemented in the pilot to use the least identifiable form of health data necessary in the aggregate within the following guidelines: (1) a disclosing entity should have its queries and results under their control (manual or automated); (2) the data being exchanged will be mock or test data, aggregated de-identified data sets or aggregated limited data sets, each with data use agreements; and (3) for other than regulated/permitted use purposes, cells with less than five observations in a cell shall be blurred by methods that reduce the accuracy of the information provided.
Discussion
- Larry Wolf asked how Query Health relates to other activities focused on quality measure initiatives. Elmore indicated that this issue has been raised during the Summer Concert Series as well as in Query Health’s Technical Workgroup. In the next few months, it is expected that decisions will be made as to which standards will be applied. Query Health will be leveraging other ongoing initiatives moving forward. Wolf suggested minimizing the diversity of requirements generated for systems to handle queries and result sets.
- In response to a question about information exchange, Elmore commented that the assumption is that the information behind an organization’s firewall is identifiable. Only in an instance of a public health permitted use would identifiable data be outside the firewall.
- Farzad Mostashari noted that Query Health’s strategy has significant architectural and certification implications in the near future. Getting in front of those and considering them early on will be critical. Clarity about the potential timeframe is needed, as it affects work in areas such as quality measurement. The business case for this effort also requires careful consideration.
- Gayle Harrell noted that there is a tremendous upside to Query Health, but there is also a significant potential for abuse that may frighten the public. She asked about the role of the HITPC in terms of providing input as this project moves forward. Deven McGraw noted that Query Health will be discussed at the next Privacy and Security Tiger Team meeting. Elmore added that the HITPC and Privacy and Security Tiger Team will be relied on to provide significant input for guiding the future of Query Health. He noted that with the exception of public health, where it is already allowed by law today to send some identifiable information, Query Health will be dealing with aggregated information and will not be exposing individual’s information. The project itself will be trying to drive towards enabling a non-centrally planned use of technology that is under the control of those responsible for the data.
- Arthur Davidson discussed the burden faced by organizations trying to participate in these important population-based efforts to analyze and move towards the learning healthcare system. He asked if there has been a discussion at the ONC level regarding the leadership role that either the ONC or the HITPC might play in harmonizing these various data models. Elmore noted that Query Health’s Technical Workgroup is examining these data models with the vision of some harmonization of standards.
- It is expected that, from the point of view of keeping it simple for an initial pilot implementation, the pilot will probably create a focus around the clinical record, whether that be an EHR or more of an HIE.
Tuesday, October 4, 2011
E-Consent Trial Project Contract Awarded
From the ONC Announcement:
"ONC's Office of the Chief Privacy Officer recently awarded a contract to find an efficient, effective, and innovative way to help patients better understand their choices regarding whether and when their health care provider can share their health information electronically, including sharing it with a health information exchange organization. The project team will design, develop, and pilot innovative ways to electronically implement existing patient choice policies, while improving business processes for health care providers.
To learn more about the E-Consent Trial project, please see the Statement of Work. ONC's formal launch of the E-Consent Trial Project will be in October."
"ONC's Office of the Chief Privacy Officer recently awarded a contract to find an efficient, effective, and innovative way to help patients better understand their choices regarding whether and when their health care provider can share their health information electronically, including sharing it with a health information exchange organization. The project team will design, develop, and pilot innovative ways to electronically implement existing patient choice policies, while improving business processes for health care providers.
To learn more about the E-Consent Trial project, please see the Statement of Work. ONC's formal launch of the E-Consent Trial Project will be in October."
Thursday, September 29, 2011
The September HIT Standards Committee Meeting
by John Halamka, Life as Healthcare CIO
Today was a big day - the end of Standards Summer Camp. We presented the HIT Standards Committee work of the past 6 months and then attended a celebratory reception at the White House.
Judy Sparrow, the ONC "national coordinator" who orchestrated all our HITSC meetings, announced her retirement last month. Jon Perlin and I presented her with a silver bowl, engraved with the words "The Standard Bearer". Thanks for all you've done, Judy.
As we discussed our Summer Camp work during the meeting, we were guided by a few basic principles:
While it might not be perfect, does it represent the best we have at this point in history?
Does it point us in the right direction?
Is it the next step in an incremental approach to refining the standards and implementation guides?
Does it support our policy objectives?
Can we update it as needed going forward through the SDO community?
Doug Fridsma presented an overview of our Summer Camp activities to date:
The Metadata Analysis Power Team lea by Stan Huff completed the standards for patient identification, provenance (which organization generated the data), and security flags. Simple XML constructs from CDA R2 and standard X.509 certificates were chosen for these requirements.
The Patient Matching Power Team led by Marc Overhage completed its analysis of best practices for patient matching, noting the types of demographics that should be captured in systems to optimize the sensitivity and specificity of patient matching applications.
The Surveillance Implementation Guide Power Team led by Chris Chute chose one implementation guide for each of the public health transactions - surveillance, reportable lab, and immunizations. We had a spirited discussion about the optional fields in the implementation guides and made it clear that we want the core elements to be the certification criteria. We do not want each state public health department to mandate different "optional" fields. Our transmittal letter will note that EHRs that send the core set should meet the certification criteria. Public health departments should accept this core set. Optional fields are just that - optional items for future reporting needs.
Farzad Mostashari, National Coordinator, framed the important discussion of transport standards by noting that we must move forward, boldly specifying what is good enough. If we specify nothing, the silos of data we have today in hospitals, clinician offices, pharmacies, and labs will persist. There's a sense of urgency to act.
The NwHIN Power Team led by Dixie Baker presented its thoughtful analysis of the 10 standards guides included in NwHIN Exchange and the 2 standards guides included in NwHIN Direct. This analysis was not a comparison of the two, but was an objective look at the suitability of each standards guide for its intended purpose to support aspects of transport functionality at a national scale. The team did not discuss their suitability for use at the local, state, or regional scale. The team did not declare "push or "pull" as a superior architecture. Their thoughtful analysis led to a very robust discussion. I'd summarize it as:
*Direct is low risk for the purpose intended, pushing data from point A to point B using SMTP/SMIME with an optional XDR (SOAP) connector. Additional work needs to be done on certificate discovery, but that will use DNS and LDAP, two well adopted technologies.
*Exchange needs additional work to ensure it scales at a national level for pull and push transactions. The S&I Framework teams are working on modular specifications that should enable a subset of Exchange components to be used, simplifying implementation and support. The Standards Committee will seek additional testimony from Exchange implementers to learn more about their experience.
*It's worthwhile to think about additional transport standards that do not yet have well specified implementation guides, such as a combination of REST, oAuth and TLS - something that Facebook, Amazon, or Google would use to create a highly scalable transport architecture.
The ePrescribing of Discharge Meds Power Team led by Jamie Ferguson presented the use of HL7 2.2-2.51 transactions to support hospital information system workflows in a manner that is compatible with Medicare Part D. We clarified that newer versions of HL7 2.x which are backward compatible should also be allowed.
The Clinical Quality Workgroup and Vocabulary Task Force led by Jamie Ferguson presented their transition plans for vocabularies, identifying the cross maps between vocabularies that need to be created and supported as we evolve from our current use of vocabularies to a future state in which there is one structured vocabulary per domain of medicine (problems, medications, labs, allergies etc).
Doug Fridsma then presented an overview of the Standards and Interoperability Framework activities and next steps:
Transitions of Care - Doug described a brilliant approach that incorporates simple XML, such as has been used in the CCR, with the expandability of the CCD. He calls this next evolution of clinical summaries "Consolidated CDA templates". It's likely that the clinical summary certification criteria will evolve to a single XML format that is easy to use, fast to implement, expandable, based on a reference model, and human readable. Well done!
Reportable Labs - In the past, standards harmonizers struggled to balance simple, easy to implement lab specifications such as ELINCS with the comprehensive and full featured lab specifications from HITSP. The S&I group created a foundation based on ELINCS that is expandable to include all the features of the HITSP specifications using a single HL7 2.51 implementation guide. Amazing work.
Provider Directories - The S&I Framework team had the courage to admit that directory standards are still evolving and need more testing/piloting before selection. DNS/LDAP approaches are likely to work well for certificate discovery. Other aspects of directories such as provider routing addresses and electronic service capabilities may be stored in web pages (microdata), LDAP (HPD), or X12 274 directory structures.
Doug also described new works in progress - Query Health for distributed data mining, Data Segmentation to manage disclosures of protected health information, and Electronic Submission of Medical Documentation for transmission to Medicare review contractors.
Finally and very importantly, the Implementation Workgroup led by Liz Johnson and Judy Murphy presented the Implementation Workgroup certification criteria analysis. We had a thoughtful discussion of each open issue and suggested a path forward for each certification item.
Truly an inspiring meeting - the most work we've ever done in a single day.
The delivery of Meaningful Use Stage 2 Standards and Certification criteria was recognized at a White House celebration by Aneesh Chopra, Chief Technology Officer and numerous members of the Obama administration senior staff. Thanks so much to Aneesh and others for celebrating our work.
As I told the Standards Committee today, I am honored to serve with this team, the hardest working Federal Advisory Committee in government. A milestone day for the country.
Today was a big day - the end of Standards Summer Camp. We presented the HIT Standards Committee work of the past 6 months and then attended a celebratory reception at the White House.
Judy Sparrow, the ONC "national coordinator" who orchestrated all our HITSC meetings, announced her retirement last month. Jon Perlin and I presented her with a silver bowl, engraved with the words "The Standard Bearer". Thanks for all you've done, Judy.
As we discussed our Summer Camp work during the meeting, we were guided by a few basic principles:
While it might not be perfect, does it represent the best we have at this point in history?
Does it point us in the right direction?
Is it the next step in an incremental approach to refining the standards and implementation guides?
Does it support our policy objectives?
Can we update it as needed going forward through the SDO community?
Doug Fridsma presented an overview of our Summer Camp activities to date:
The Metadata Analysis Power Team lea by Stan Huff completed the standards for patient identification, provenance (which organization generated the data), and security flags. Simple XML constructs from CDA R2 and standard X.509 certificates were chosen for these requirements.
The Patient Matching Power Team led by Marc Overhage completed its analysis of best practices for patient matching, noting the types of demographics that should be captured in systems to optimize the sensitivity and specificity of patient matching applications.
The Surveillance Implementation Guide Power Team led by Chris Chute chose one implementation guide for each of the public health transactions - surveillance, reportable lab, and immunizations. We had a spirited discussion about the optional fields in the implementation guides and made it clear that we want the core elements to be the certification criteria. We do not want each state public health department to mandate different "optional" fields. Our transmittal letter will note that EHRs that send the core set should meet the certification criteria. Public health departments should accept this core set. Optional fields are just that - optional items for future reporting needs.
Farzad Mostashari, National Coordinator, framed the important discussion of transport standards by noting that we must move forward, boldly specifying what is good enough. If we specify nothing, the silos of data we have today in hospitals, clinician offices, pharmacies, and labs will persist. There's a sense of urgency to act.
The NwHIN Power Team led by Dixie Baker presented its thoughtful analysis of the 10 standards guides included in NwHIN Exchange and the 2 standards guides included in NwHIN Direct. This analysis was not a comparison of the two, but was an objective look at the suitability of each standards guide for its intended purpose to support aspects of transport functionality at a national scale. The team did not discuss their suitability for use at the local, state, or regional scale. The team did not declare "push or "pull" as a superior architecture. Their thoughtful analysis led to a very robust discussion. I'd summarize it as:
*Direct is low risk for the purpose intended, pushing data from point A to point B using SMTP/SMIME with an optional XDR (SOAP) connector. Additional work needs to be done on certificate discovery, but that will use DNS and LDAP, two well adopted technologies.
*Exchange needs additional work to ensure it scales at a national level for pull and push transactions. The S&I Framework teams are working on modular specifications that should enable a subset of Exchange components to be used, simplifying implementation and support. The Standards Committee will seek additional testimony from Exchange implementers to learn more about their experience.
*It's worthwhile to think about additional transport standards that do not yet have well specified implementation guides, such as a combination of REST, oAuth and TLS - something that Facebook, Amazon, or Google would use to create a highly scalable transport architecture.
The ePrescribing of Discharge Meds Power Team led by Jamie Ferguson presented the use of HL7 2.2-2.51 transactions to support hospital information system workflows in a manner that is compatible with Medicare Part D. We clarified that newer versions of HL7 2.x which are backward compatible should also be allowed.
The Clinical Quality Workgroup and Vocabulary Task Force led by Jamie Ferguson presented their transition plans for vocabularies, identifying the cross maps between vocabularies that need to be created and supported as we evolve from our current use of vocabularies to a future state in which there is one structured vocabulary per domain of medicine (problems, medications, labs, allergies etc).
Doug Fridsma then presented an overview of the Standards and Interoperability Framework activities and next steps:
Transitions of Care - Doug described a brilliant approach that incorporates simple XML, such as has been used in the CCR, with the expandability of the CCD. He calls this next evolution of clinical summaries "Consolidated CDA templates". It's likely that the clinical summary certification criteria will evolve to a single XML format that is easy to use, fast to implement, expandable, based on a reference model, and human readable. Well done!
Reportable Labs - In the past, standards harmonizers struggled to balance simple, easy to implement lab specifications such as ELINCS with the comprehensive and full featured lab specifications from HITSP. The S&I group created a foundation based on ELINCS that is expandable to include all the features of the HITSP specifications using a single HL7 2.51 implementation guide. Amazing work.
Provider Directories - The S&I Framework team had the courage to admit that directory standards are still evolving and need more testing/piloting before selection. DNS/LDAP approaches are likely to work well for certificate discovery. Other aspects of directories such as provider routing addresses and electronic service capabilities may be stored in web pages (microdata), LDAP (HPD), or X12 274 directory structures.
Doug also described new works in progress - Query Health for distributed data mining, Data Segmentation to manage disclosures of protected health information, and Electronic Submission of Medical Documentation for transmission to Medicare review contractors.
Finally and very importantly, the Implementation Workgroup led by Liz Johnson and Judy Murphy presented the Implementation Workgroup certification criteria analysis. We had a thoughtful discussion of each open issue and suggested a path forward for each certification item.
Truly an inspiring meeting - the most work we've ever done in a single day.
The delivery of Meaningful Use Stage 2 Standards and Certification criteria was recognized at a White House celebration by Aneesh Chopra, Chief Technology Officer and numerous members of the Obama administration senior staff. Thanks so much to Aneesh and others for celebrating our work.
As I told the Standards Committee today, I am honored to serve with this team, the hardest working Federal Advisory Committee in government. A milestone day for the country.
Monday, September 19, 2011
September HIT Policy Committee on Query Health
The HIT Policy Committee recently reviewed Query Health, the ONC sponsored initiative to define standards and protocols for distributed population queries.
Thursday, September 15, 2011
Health Wonk Review is up
David Williams at the Health Business Blog hosts Health Wonk Review, the very best of the Health Policy blogosphere.
Wednesday, September 7, 2011
Introducing Query Health
The Office of the National Coordinator for Health IT (ONC) recently hosted the Summer Concert Series on Distributed Population Queries. Practitioners presented their work related to distributed population queries. They illustrated their approach and rationale for using aggregated information from distributed queries to improve healthcare quality, medical research, public health monitoring and prevention, among others. These are vitally important applications to the health of patients and populations.
Query Health will establish standards for distributed population queries of electronic health records and other sources of health information. The ultimate success of the effort relies on the participation of a wide range of stakeholders including patient advocates, clinicians, health IT experts, health systems, payers and other interested parties. Query Health is an Open Government Initiative that is consensus-based, transparent, and open. Those interested in working with ONC, national health leaders and innovators can get involved by signing up at QueryHealth.org.
The Query Health launch included presentations by Farzad Mostashari (National Coordinator for Health IT), Todd Park (Chief Technology Officer HHS), Doug Fridsma (ONC Director of Standards & Interoperability) and me (ONC Coordinator for Query Health).
Query Health Launch from S&I Framework on Vimeo.
Query Health will establish standards for distributed population queries of electronic health records and other sources of health information. The ultimate success of the effort relies on the participation of a wide range of stakeholders including patient advocates, clinicians, health IT experts, health systems, payers and other interested parties. Query Health is an Open Government Initiative that is consensus-based, transparent, and open. Those interested in working with ONC, national health leaders and innovators can get involved by signing up at QueryHealth.org.
The Query Health launch included presentations by Farzad Mostashari (National Coordinator for Health IT), Todd Park (Chief Technology Officer HHS), Doug Fridsma (ONC Director of Standards & Interoperability) and me (ONC Coordinator for Query Health).
Query Health Launch from S&I Framework on Vimeo.
Tuesday, September 6, 2011
i2b2 / SHRINE - Query Health Summer Concert Series
Informatics for Integrating Biology and the Bedside (i2b2) is one of the projects sponsored by the NIH National Centers for Biomedical Computing. The purpose of this project is to provide clinical investigators with the software tools necessary to integrate medical record and clinical research data in the genomics age, a software suite to construct and integrate the modern clinical research chart. Patient medical record data, including diagnoses, medications, laboratory values, and outcome variables, along with the accompanying patient demographics and encounter information can be combined with clinical research data into a single cohesive unit and be queried in a manner that is unprecedented in clinical research. This is achieved by maintaining specific aspects of ontology management, data ownership, and patient privacy while overlaying a generic data architecture. The generic data model and the service oriented architecture of i2b2 lends itself to a natural implementation of a distributed query system, for example the Shared Health Research Information Network (SHRINE) at Harvard. Shawn Murphy and Zak Kohane present.
Query Health - i2b2/SHRINE Presentation from S&I Framework on Vimeo.
Monday, September 5, 2011
Observational Medical Outcomes Partnership - Query Health Summer Concert Series
OMOP is a public-private partnership chaired by the FDA and administered by the Foundation for the National Institutes of Health. OMOP conducts methodological research to inform the appropriate use of observational healthcare data including administrative data and electronic health records. OMOP has established a central research laboratory and a distributed data network of over 150 million lives, and has developed a series of standardized analytics to characterize data sources to support the understanding of the effects of medical products. In this discussion the OMOP team presents the OMOP common clinical information model and applications of systematic tools across the data network. The presentation demonstrates how these tools have been applied for many use cases identified as priorities within the ONC Query Health initiative. Patrick Ryan, Marc Overhage and Tom Scarnecchia present.
Sunday, September 4, 2011
Regenstrief Distributed Query - Query Health Summer Concer Series
Created by the Regenstrief Institute in the mid-1990's, the Indiana Network for Patient Care (INPC) is one of the nation’s most comprehensive and longest tenured health information exchanges, containing more than 3.1 billion coded standardized clinical observations, a global patient index containing more than 20 million person entities that represent more than 12 million unique persons, and a physician cohort exceeding 19,000 providers. The system allows physicians working in a variety of clinical settings, with the patient's permission, to view as a single virtual record all previous care at dozens of Indiana hospitals. A centrally managed federated clinical data repository, the INPC supports many other use cases including public health reporting, clinical research, and quality reporting. In this presentation, the INPC framework and supported applications are described. Shaun Grannis presents.
Saturday, September 3, 2011
Distribute and BioSense - Query Health Summer Concert Series
Distribute
The Distribute project was initiated by the International Society for Disease Surveillance (ISDS) in 2006 to pilot influenza-like illness (ILI) monitoring using data aggregated from syndromic surveillance systems operated by state and local health departments. In 2009, following the first wave of H1N1 influenza pandemic, it was rapidly expanded to enhance ILI surveillance, covering approximately one-third of US emergency department visits. Staff from the CDC (BioSense program and Influenza Division) and the Public Health Informatics Institute (PHII) supported ISDS during the Distribute scale-up, including assisting with outreach and direct technical support to health departments, and in providing timely analysis. Approximately half of the sites currently contributing ILI data to Distribute come through BioSense or linking health departments syndromic surveillance systems to CDC. David Buckeridge presents.
BioSense
BioSense is a program of the Centers for Disease Control and Prevention (CDC) that tracks health problems as they evolve and provides public health officials with the data, information and tools they need to better prepare for and coordinate responses to safeguard and improve the health of the American people. By November 2011, the redesigned BioSense (or BioSense 2.0) will develop a community-controlled environment (architecturally distributed in a cloud-based model) that state and local health departments can access to support potential expansions of their syndromic surveillance systems under the Meaningful Use program. By integrating local and state-level data into a cohesive “picture,” the BioSense Program will improve its utility for state and local users. Taha Kass-Hout presents.
Query Health - Distribute & BioSense Presentations from S&I Framework on Vimeo.
The Distribute project was initiated by the International Society for Disease Surveillance (ISDS) in 2006 to pilot influenza-like illness (ILI) monitoring using data aggregated from syndromic surveillance systems operated by state and local health departments. In 2009, following the first wave of H1N1 influenza pandemic, it was rapidly expanded to enhance ILI surveillance, covering approximately one-third of US emergency department visits. Staff from the CDC (BioSense program and Influenza Division) and the Public Health Informatics Institute (PHII) supported ISDS during the Distribute scale-up, including assisting with outreach and direct technical support to health departments, and in providing timely analysis. Approximately half of the sites currently contributing ILI data to Distribute come through BioSense or linking health departments syndromic surveillance systems to CDC. David Buckeridge presents.
BioSense
BioSense is a program of the Centers for Disease Control and Prevention (CDC) that tracks health problems as they evolve and provides public health officials with the data, information and tools they need to better prepare for and coordinate responses to safeguard and improve the health of the American people. By November 2011, the redesigned BioSense (or BioSense 2.0) will develop a community-controlled environment (architecturally distributed in a cloud-based model) that state and local health departments can access to support potential expansions of their syndromic surveillance systems under the Meaningful Use program. By integrating local and state-level data into a cohesive “picture,” the BioSense Program will improve its utility for state and local users. Taha Kass-Hout presents.
Query Health - Distribute & BioSense Presentations from S&I Framework on Vimeo.
Friday, September 2, 2011
DARTNet - Query Health Summer Concert Series
DARTNet is a collaborative of seven electronic health record based research networks that have agreed to standardize data codification and underlying analytical data models. The groups work together to advance research methodology from the macro level, such as study design, to the micro level, such as analytical decisions. All participants share an underlying practice-based research framework on which they are adding the ability to conduct large comparative effectiveness and pragmatic clinical trials. The groups ares constantly looking to expand data sources available to improve clinical care and research capabilities. Wilson Pace presents.
Query Health - DARTNet Presentation from S&I Framework on Vimeo.
Query Health - DARTNet Presentation from S&I Framework on Vimeo.
Thursday, September 1, 2011
Hub Population Health System - Query Health Summer Concert Series
The New York City Department of Health's Hub Population Health System ("The Hub") enables the distribution of electronic health record queries, targeted clinical decision support, and secure messages to more than 350 small practices and large community health centers using eClinicalWorks in New York City, covering 1.1 million patients. Query results are received as aggregate counts for population health purposes. Over 600 unique queries have been run over 80,000 times covering the areas of population health evaluation, EHR system utilization, Hub system performance, syndromic surveillance, etc. Jesse Singer and Michael Buck present
Wednesday, August 31, 2011
Population CCR - Query Health Summer Concert Series
Population CCR is an approach for simplifying and integrating performance reporting and decision support. It fulfills a need for decoupling of analytics from current and future health IT systems. It eases the creation of rules by non-programmers and harmonizes the representation of clinical data across patient records, performance reporting, and decision support - all by using widely accepted standard technologies. Steven Waldren presents.
Query Health - Population CCR Presentation from S&I Framework on Vimeo.
Query Health - Population CCR Presentation from S&I Framework on Vimeo.
Tuesday, August 30, 2011
caGrid - Query Health Summer Concert Series
caGrid is an open‐source framework that addresses the needs of a heterogeneous community to access, integrate, and analyze biomedical data of diverse nature and source. This platform allows diverse, authorized applications, running on multiple platforms, to access appropriate data (both individual level and aggregated) from distributed sources. It permits simple access to unrestricted data using standard internet technology as well as secure access by authorized “virtual communities” to sensitive, restricted digital resources using community‐developed caGrid technology. Ken Buetow presents.
Query Health - caGrid Presentation from S&I Framework on Vimeo.
Query Health - caGrid Presentation from S&I Framework on Vimeo.
Monday, August 29, 2011
UPHN - Query Health Summer Concert Series
New York’s Universal Public Health Node (UPHN) Initiative is a strategic organizational process, informatics approach and technical infrastructure to transform public health practice through health information exchange in New York. The UPHN enables the integration of the public health practice across the health enterprise as part of the business model for effective and economical health care delivery. UPHN helps improve the efficacy of public health practice through authorized program access to integrated longitudinal health information assets. Ivan Gotham, Lee Jones and Vince Lewis present.
Query Health - UPHN Presentation from S&I Framework on Vimeo.
Query Health - UPHN Presentation from S&I Framework on Vimeo.
Monday, August 22, 2011
Angular Momentum - a true love story
http://blog.xkcd.com/2011/06/30/family-illness/)
Published under Creative Commons license

Published under Creative Commons license
Thursday, August 18, 2011
The August HIT Standards Committee Meeting
By John Halamka, Life as a Healthcare CIO
The August meeting of the HIT Standards Committee (the 28th meeting of this FACA) was a milestone in parsimony. As you'll see, we approved a set of vocabulary recommendations and public health standards that represent harmony as well the fewest number of standards possible for the intended purpose.
Since April, we've been working hard on Summer Camp. At our September meeting, we'll wrap up all that work and hand off the finished standards recommendations to ONC for regulation writing.
Per our Summer Camp plan, the August meeting included final recommendations on vocabulary standards for quality measures, final recommendations on all public health transactions, preliminary recommendations on patient matching, and preliminary recommendations on transport/security standards. We also heard from the Standards and Interoperability Framework team about their work and the Implementation Workgroup on their review of Certification Criteria.
This was a powerful meeting, discussing the standards that so many people have been working on for the past decade - one vocabulary standard for each class of data used in quality measures, one approach to public health transactions, one approach to transfer of care summaries, one approach to laboratory results, and a building block approach to data transmission that supports the portfolio of health information exchange options.
We began with the final recommendations from the Clinical Quality Workgroup and Vocabulary Task force on vocabulary standards. Per the marching orders we gave them, they selected one vocabulary standard for each domain - problems, medications, allergies, labs etc. SNOMED-CT and LOINC are the default vocabularies used whenever possible. The committee approved these recommendations by consensus with 2 caveats
-the Implementation Workgroup will be charged with ongoing review of the implementation burden of using these standards in a variety of settings
-the September meeting of the HIT Standards Committee will include discussion of a transition plan for those vocabulary standards required for Stage 1 that are being retired/replaced in Stage 2.
Marc Overhage presented best practices for patient matching, identifying the metadata that should be standardized in patient records and health information exchange. These recommendations are complementary to the metadata standard recommendations in the Advanced Notice of Proposed Rulemaking, enabling stakeholders to optimize a patient matching strategy as needed for their applications using best practices and evidence from industry experience.
Chris Chute presented the recommendations for public health standards - one HL7 2.51 implementation guide for surveillance, one HL7 2.51 implementation guide for immunizations and one HL7 2.51 implementation guide for reportable labs. The optionality specified in meaningful use stage 1 was eliminated and the end result are simple un-ambiguous implementation guides for public health.
Dixie Baker presented the preliminary recommendations for building blocks that support data exchange in both "push" and "pull" models. The key innovation in Dixie's is the process for reviewing existing standards for appropriateness, adoption, maturity, and currency.
Jitin Asnaani from ONC presented the S&I Framework update including Certificates, Lab Results, Transitions of Care, and Provider Directories. These will be reviewed and hopefully turned into guidance for ONC in the next few months.
Finally, Judy Murphy and Liz Johnson presented their work on certification criteria.
A remarkable meeting from a world class team. I'm proud to be a part of it!
The August meeting of the HIT Standards Committee (the 28th meeting of this FACA) was a milestone in parsimony. As you'll see, we approved a set of vocabulary recommendations and public health standards that represent harmony as well the fewest number of standards possible for the intended purpose.
Since April, we've been working hard on Summer Camp. At our September meeting, we'll wrap up all that work and hand off the finished standards recommendations to ONC for regulation writing.
Per our Summer Camp plan, the August meeting included final recommendations on vocabulary standards for quality measures, final recommendations on all public health transactions, preliminary recommendations on patient matching, and preliminary recommendations on transport/security standards. We also heard from the Standards and Interoperability Framework team about their work and the Implementation Workgroup on their review of Certification Criteria.
This was a powerful meeting, discussing the standards that so many people have been working on for the past decade - one vocabulary standard for each class of data used in quality measures, one approach to public health transactions, one approach to transfer of care summaries, one approach to laboratory results, and a building block approach to data transmission that supports the portfolio of health information exchange options.
We began with the final recommendations from the Clinical Quality Workgroup and Vocabulary Task force on vocabulary standards. Per the marching orders we gave them, they selected one vocabulary standard for each domain - problems, medications, allergies, labs etc. SNOMED-CT and LOINC are the default vocabularies used whenever possible. The committee approved these recommendations by consensus with 2 caveats
-the Implementation Workgroup will be charged with ongoing review of the implementation burden of using these standards in a variety of settings
-the September meeting of the HIT Standards Committee will include discussion of a transition plan for those vocabulary standards required for Stage 1 that are being retired/replaced in Stage 2.
Marc Overhage presented best practices for patient matching, identifying the metadata that should be standardized in patient records and health information exchange. These recommendations are complementary to the metadata standard recommendations in the Advanced Notice of Proposed Rulemaking, enabling stakeholders to optimize a patient matching strategy as needed for their applications using best practices and evidence from industry experience.
Chris Chute presented the recommendations for public health standards - one HL7 2.51 implementation guide for surveillance, one HL7 2.51 implementation guide for immunizations and one HL7 2.51 implementation guide for reportable labs. The optionality specified in meaningful use stage 1 was eliminated and the end result are simple un-ambiguous implementation guides for public health.
Dixie Baker presented the preliminary recommendations for building blocks that support data exchange in both "push" and "pull" models. The key innovation in Dixie's is the process for reviewing existing standards for appropriateness, adoption, maturity, and currency.
Jitin Asnaani from ONC presented the S&I Framework update including Certificates, Lab Results, Transitions of Care, and Provider Directories. These will be reviewed and hopefully turned into guidance for ONC in the next few months.
Finally, Judy Murphy and Liz Johnson presented their work on certification criteria.
A remarkable meeting from a world class team. I'm proud to be a part of it!
Monday, August 15, 2011
hQuery - Query Health Summer Concert Series
Andy Gregorowicz presents MITRE’s work on hQuery. hQuery uses pervasive internet-based technologies to deliver flexible easy-to-understand queries and distributed ultra-large scale query execution capabilities.
Query Health - hQuery Presentation from S&I Framework on Vimeo.
Query Health - hQuery Presentation from S&I Framework on Vimeo.
Tuesday, August 9, 2011
PopMedNet - Query Health Summer Concert Series
PopMedNet uses distributed networks to analyze data from multiple organizations in order to aggregate information for secondary use (use other than direct patient care or administration) such as disease surveillance, comparative effectiveness, and medical product safety. In one example, the FDA identified final specifications for a query to monitor the cardiac outcomes of a particular drug. Using PopMedNet, the specs were distributed to 17 data partners with a combined 99 million individual users. Within an incredible turnaround time of two days a report was delivered outlining statistics about new users (including distributions by age, sex, year, and health plan), first treatment exposure duration, and cardiac outcome diagnoses during treatment. Platt and Brown also emphasized the importance of governance among participants in a distributed network in order to perform successful queries. PopMedNet’s flexibility allows for each network of participants to create, administer and govern their own networks. However, this puts the responsibility of governance on the individual networks to determine the data standards and best practices for their needs. Therefore, the success of PopMedNet relies heavily on its support for the governance principles of the participating organizations. Rich Platt and Jeff Brown of Harvard Medical School’s Department of Population Medicine present.
Query Health - PopMedNet Presentation from siframework on Vimeo.
Query Health - PopMedNet Presentation from siframework on Vimeo.
Monday, August 1, 2011
Sunday, July 31, 2011

Monday, July 25, 2011
Distributed population queries - a national priority
By Rich Elmore, Initiative Coordinator
Office of the National Coordinator for Health Information Technology
This August, ONC will be sponsoring the “Summer Concert Series” on the state-of-the-art of distributed population queries. The “Summer Concert Series” webinar presentations will provide tremendous insight from a real-world perspective to interested stakeholders on practitioners’ experience with distributed queries.
Distributed population queries can be applied to public health surveillance, research, quality measures, chronic disease stratification and many other purposes. These queries return aggregate information from a standard clinical information model, leaving protected health information safely behind the health care organizations’ firewalls.
The use of distributed population queries for clinical insight has been hindered by organizational limitations on data sharing, inconsistencies in the expression of clinical concepts and lack of standards for distributed queries. This has ultimately limited their use, with a few notable exceptions, to large healthcare organizations with more sophisticated IT infrastructures and deeper research budgets.
One may ask “Why not just centralize the data?” Well for one, for non-regulated purposes many healthcare organizations will choose not to loosen their control over their data. Also, as a matter of principle, patient level data shouldn’t be exchanged when aggregate level information will do. Finally, keeping data close to the source may improve adaptability to dynamic information needs and responsiveness to patient information sharing preferences.
As we approach critical mass of deployments of certified and standardized Electronic Health Record (EHR) systems, we may for the first time be able to consider broader use of distributed population queries. EHR certification standards require greater adherence to standardized vocabularies and information exchange structures. While challenges with comparative data will remain, Meaningful Use Stage 2 will likely further improve vocabulary, message and transport standards.
As an example of distributed queries, Wes Rishel recently explored the changing public health reporting needs during an epidemic. He suggested use of distributed population queries to “send questions to the data.”
For another example, until recently the most extensive research to identify comorbidities for autism patients was a multi-year study on 163 patients. Zak Kohane’s new work on autism patients and comorbidities used distributed queries across the i2b2 SHRINE network linking 4 Boston hospitals. By tapping into a much larger patient population, his analysis provided greater insight into the comorbidities. The time required to conduct the research was 3 weeks. Distributed queries delivered these deeper insights by reaching an order of magnitude more patients and did so in two orders of magnitude less time.
Query Health, a public/private partnership project, will be launched in September to take some practical first steps towards this national priority. The ultimate goal of the Query Health initiative will be to define the standards and services to better enable the use of this distributed approach.
Please mark your calendars for the “Summer Concert Series” in August and the Query Health project launch on September 6th at 3 PM ET. Visit the Query Health web site for more information on these events.
Thursday, July 21, 2011
The July HIT Standards Committee Meeting
by John Halamka, Life as a Healthcare CIO
Farzad Mostashari, national coordinator for healthcare IT, began the meeting with a discussion of the issues we have always faced while harmonizing standards. Standards that are widely adopted by the marketplace and are well tested make harmonization easy. However, many standards are mature but not widely adopted or novel but not well tested. We want to encourage innovation and use market adoption as a measure of our success. It's clear that at times we'll have to consider new standards that seem very reasonable for the purpose intended and test them in real world scenarios before forcing top down adoption through regulation. Bottom up adoption of standards that are implemented and improved by stakeholders is a better approach.
Per the Standards Summer Camp schedule, the July HIT Standards Committee meeting focused on
Vocabulary recommendations
ePrescribing of discharged medications recommendations
Patient Matching recommendations
Syndromic Surveillance recommendations
Jim Walker, chair of the Clinical Quality workgroup, presented an overview of the vocabulary work done to support all our clinical coordination and quality measurement activities. The charter for the group was to select the minimum number of vocabulary standards with the minimum number of values to meet the requirements of meaningful use stages 2 and 3. Reducing the number of standards makes mapping between different vocabularies much easier. The workgroup used SNOMED-CT and LOINC wherever possible and tried to select one vocabulary per domain (allergies, labs, medications etc). Examples of their selections include
Adverse Drug effect - RxNorm for medications, SNOMED-CT for non-medication substances, SNOMED-CT for severity of reaction
Patient characteristics - ISO 639-2 for preferred language, HL7 for administrative gender, PHIN-VADS (Centers for Disease Control) for Race/Ethnicity
Condition/Diagnosis/Problem - SNOMED-CT
Non-lab Diagnostic study - LOINC for name, SNOMED-CT for appropriate findings, UCUM for Units
A rich discussion followed. Points of concern included:
*Using RxNorm for all medications including vaccines, even though CVX is the required vaccine vocabulary for Meaningful Use stage 1. We clarified this with an example from Beth Israel Deaconess Medical Center:
BIDMC uses First Data Bank as the medication vocabulary for its internal systems. However, when BIDMC sends clinical summaries, it maps FDB to RxNorm for all drug names. When BIDMC sends immunization records to public health, it uses CVX codes. Thus, the HIT Standards Committee will not specify the vocabularies used within enterprise applications, just those vocabularies that are needed for specific purposes when data is transmitted between entities.
Next, Doug Fridsma began a discussion of our Summer Camp items, noting the many projects of the S&I framework are proceeding according to plan.
Scott Robertson presented the work of the Discharge Medications Power Team. They recommended HL7 and NCPDP script as reasonable standards for sending discharge medication orders to hospital pharmacies and retail pharmacies.
Discussion followed regarding two specific points - their recommendations did not include a specific version of HL7, since existing Medicare Part D regulations do not specify an HL7 version. The power team will make additional more specific HL7 recommendations. There was discussion about the specific aspects of RxNorm that constrain the way dose and route are specified. The HIT Standards Committee members felt additional work was needed before mandating this level of specificity, so our recommendations will include RxNorm for medication name, but not additional specificity for dose and route vocabularies at this time.
Next, Marc Overhage presented the recommendations of thePatient Matching Power Team. The scope of the Patient Matching work is to provide guidance to implementers who want to understand best practices for the use of demographics in machine to machine matching of patient identity. Per the RAND Report, use of different fields results in variation of specificity and sensitivity. Some fields such as social security number (or a subset of it) greatly increase specificity, resulting in fewer false positives such as matching the wrong patient. However, social security number is controversial because of the potential for identity theft and the fact that immigrants may not have one. The final report will take into account all these observations.
Chris Chute presented the recommendations of the Surveillance Implementation Guide Power Team, which aims to specify one implementation guide for each public health transaction. They are studying the difference between HL7 2.31 and 2.51 as well as considering the potential for public health entities to use CDA constructs.
Dixie Baker presented a project plan for the NwHIN Power Team,which aims to specify a set of building blocks for secure transport of data in multiple architectures.
Finally, Judy Murphy and Liz Johnson presented their plans for the Implementation Workgroup, collecting lessons learned from certification and attestation.
We're on track with Summer Camp. Our next meeting in August will include the final recommendations for
Simple Lab Results
Transitions of Care
CDA Cleanup
Patient Matching
Vocabulary
Every meeting with the HIT Standards Committee (this was our 27th) brings us closer as a working team. We're transparent and passionate, openly sharing all the issues and concerns about the standards we're selecting. Coordination with all the moving parts (ONC, Policy Committee, S&I Framework) keeps getting better and better.
Thus far, Summer Camp is a winner and I am confident we'll meet all our September deadlines for offering recommendations to ONC in preparation for Meaningful Use Stage 2 regulations.
Farzad Mostashari, national coordinator for healthcare IT, began the meeting with a discussion of the issues we have always faced while harmonizing standards. Standards that are widely adopted by the marketplace and are well tested make harmonization easy. However, many standards are mature but not widely adopted or novel but not well tested. We want to encourage innovation and use market adoption as a measure of our success. It's clear that at times we'll have to consider new standards that seem very reasonable for the purpose intended and test them in real world scenarios before forcing top down adoption through regulation. Bottom up adoption of standards that are implemented and improved by stakeholders is a better approach.
Per the Standards Summer Camp schedule, the July HIT Standards Committee meeting focused on
Vocabulary recommendations
ePrescribing of discharged medications recommendations
Patient Matching recommendations
Syndromic Surveillance recommendations
Jim Walker, chair of the Clinical Quality workgroup, presented an overview of the vocabulary work done to support all our clinical coordination and quality measurement activities. The charter for the group was to select the minimum number of vocabulary standards with the minimum number of values to meet the requirements of meaningful use stages 2 and 3. Reducing the number of standards makes mapping between different vocabularies much easier. The workgroup used SNOMED-CT and LOINC wherever possible and tried to select one vocabulary per domain (allergies, labs, medications etc). Examples of their selections include
Adverse Drug effect - RxNorm for medications, SNOMED-CT for non-medication substances, SNOMED-CT for severity of reaction
Patient characteristics - ISO 639-2 for preferred language, HL7 for administrative gender, PHIN-VADS (Centers for Disease Control) for Race/Ethnicity
Condition/Diagnosis/Problem - SNOMED-CT
Non-lab Diagnostic study - LOINC for name, SNOMED-CT for appropriate findings, UCUM for Units
A rich discussion followed. Points of concern included:
*Using RxNorm for all medications including vaccines, even though CVX is the required vaccine vocabulary for Meaningful Use stage 1. We clarified this with an example from Beth Israel Deaconess Medical Center:
BIDMC uses First Data Bank as the medication vocabulary for its internal systems. However, when BIDMC sends clinical summaries, it maps FDB to RxNorm for all drug names. When BIDMC sends immunization records to public health, it uses CVX codes. Thus, the HIT Standards Committee will not specify the vocabularies used within enterprise applications, just those vocabularies that are needed for specific purposes when data is transmitted between entities.
Next, Doug Fridsma began a discussion of our Summer Camp items, noting the many projects of the S&I framework are proceeding according to plan.
Scott Robertson presented the work of the Discharge Medications Power Team. They recommended HL7 and NCPDP script as reasonable standards for sending discharge medication orders to hospital pharmacies and retail pharmacies.
Discussion followed regarding two specific points - their recommendations did not include a specific version of HL7, since existing Medicare Part D regulations do not specify an HL7 version. The power team will make additional more specific HL7 recommendations. There was discussion about the specific aspects of RxNorm that constrain the way dose and route are specified. The HIT Standards Committee members felt additional work was needed before mandating this level of specificity, so our recommendations will include RxNorm for medication name, but not additional specificity for dose and route vocabularies at this time.
Next, Marc Overhage presented the recommendations of thePatient Matching Power Team. The scope of the Patient Matching work is to provide guidance to implementers who want to understand best practices for the use of demographics in machine to machine matching of patient identity. Per the RAND Report, use of different fields results in variation of specificity and sensitivity. Some fields such as social security number (or a subset of it) greatly increase specificity, resulting in fewer false positives such as matching the wrong patient. However, social security number is controversial because of the potential for identity theft and the fact that immigrants may not have one. The final report will take into account all these observations.
Chris Chute presented the recommendations of the Surveillance Implementation Guide Power Team, which aims to specify one implementation guide for each public health transaction. They are studying the difference between HL7 2.31 and 2.51 as well as considering the potential for public health entities to use CDA constructs.
Dixie Baker presented a project plan for the NwHIN Power Team,which aims to specify a set of building blocks for secure transport of data in multiple architectures.
Finally, Judy Murphy and Liz Johnson presented their plans for the Implementation Workgroup, collecting lessons learned from certification and attestation.
We're on track with Summer Camp. Our next meeting in August will include the final recommendations for
Simple Lab Results
Transitions of Care
CDA Cleanup
Patient Matching
Vocabulary
Every meeting with the HIT Standards Committee (this was our 27th) brings us closer as a working team. We're transparent and passionate, openly sharing all the issues and concerns about the standards we're selecting. Coordination with all the moving parts (ONC, Policy Committee, S&I Framework) keeps getting better and better.
Thus far, Summer Camp is a winner and I am confident we'll meet all our September deadlines for offering recommendations to ONC in preparation for Meaningful Use Stage 2 regulations.
Subscribe to:
Posts (Atom)







{kind=link}